Ariadne Thread: A Document Pipeline That Saves Your Agents 100x in Tokens
Here’s the problem: every time you feed a raw PDF to an AI agent, you’re burning tokens on formatting, boilerplate, and structure that the model has to wade through to find the one paragraph it actually needs. A 50-page contract becomes 100,000 tokens of context. The answer was in two paragraphs worth 500 tokens.
That’s a 200x waste. And it’s not just expensive — it degrades quality. The more noise in the context, the worse the model performs.

What Ariadne Thread does
Ariadne Thread is an open source document extraction and retrieval pipeline. It converts documents into clean Markdown, chunks them intelligently, embeds them for semantic search, and stores everything in Postgres with pgvector. When your agent needs information, it searches and gets back just the relevant chunks — not the entire document.
The pipeline has seven steps. Four are free.
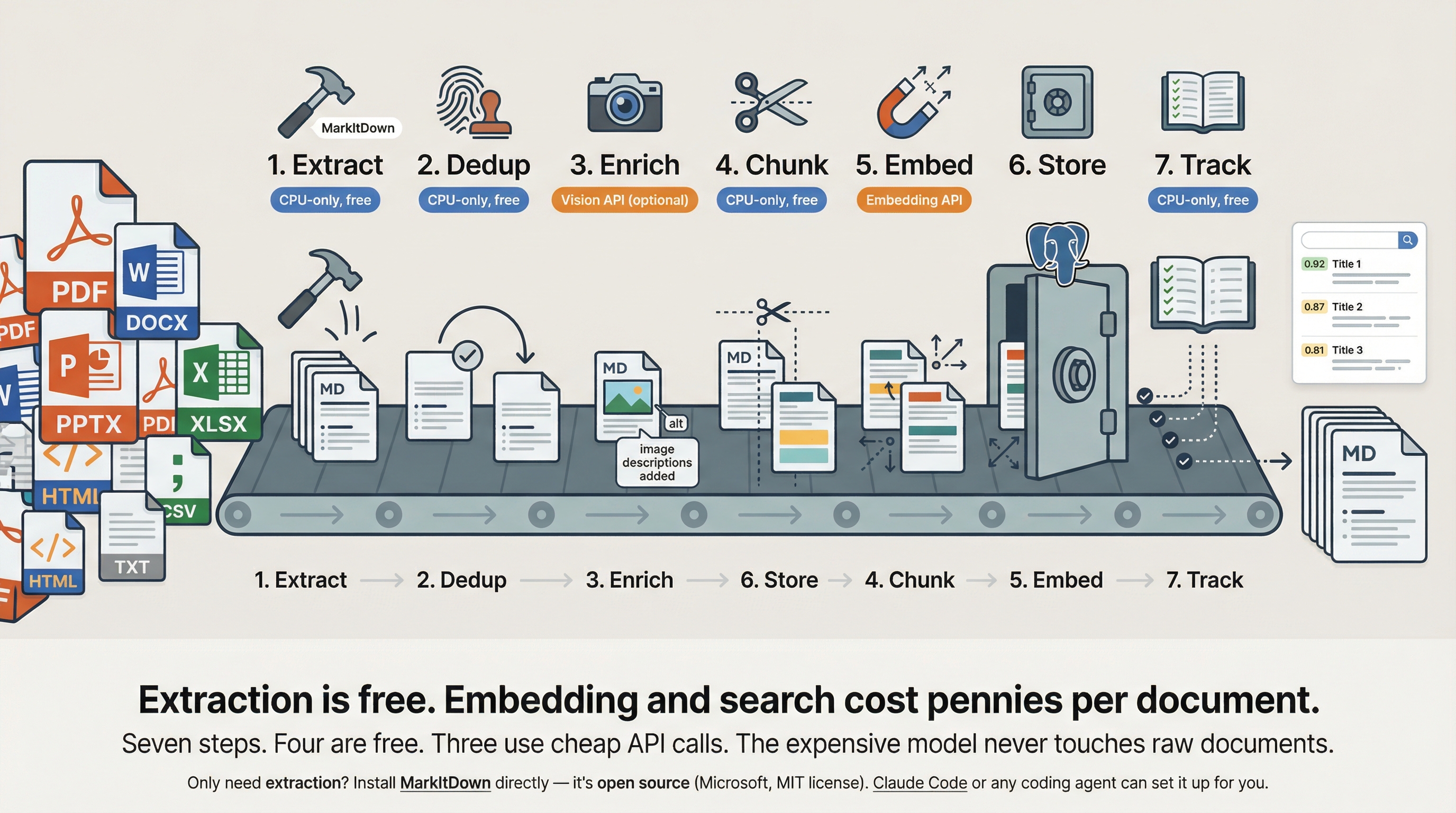
- Extract — MarkItDown converts 20+ formats to clean Markdown (free, MIT licensed)
- Dedup — Fingerprinting prevents reprocessing the same document (free)
- Enrich — Vision API describes images in the document (optional, cheap)
- Chunk — Intelligent splitting preserves context (free)
- Embed — Embedding API creates vector representations for search (~$0.001/document)
- Store — Postgres with pgvector holds everything (free with hosting)
- Track — Provenance ledger records who processed what and when (free)
The expensive model never touches raw documents. That’s the point.
If you only need extraction — converting documents to Markdown without search — you can install MarkItDown directly. It’s open source and free. Ariadne Thread adds the search, storage, and retrieval layer on top.
Format coverage
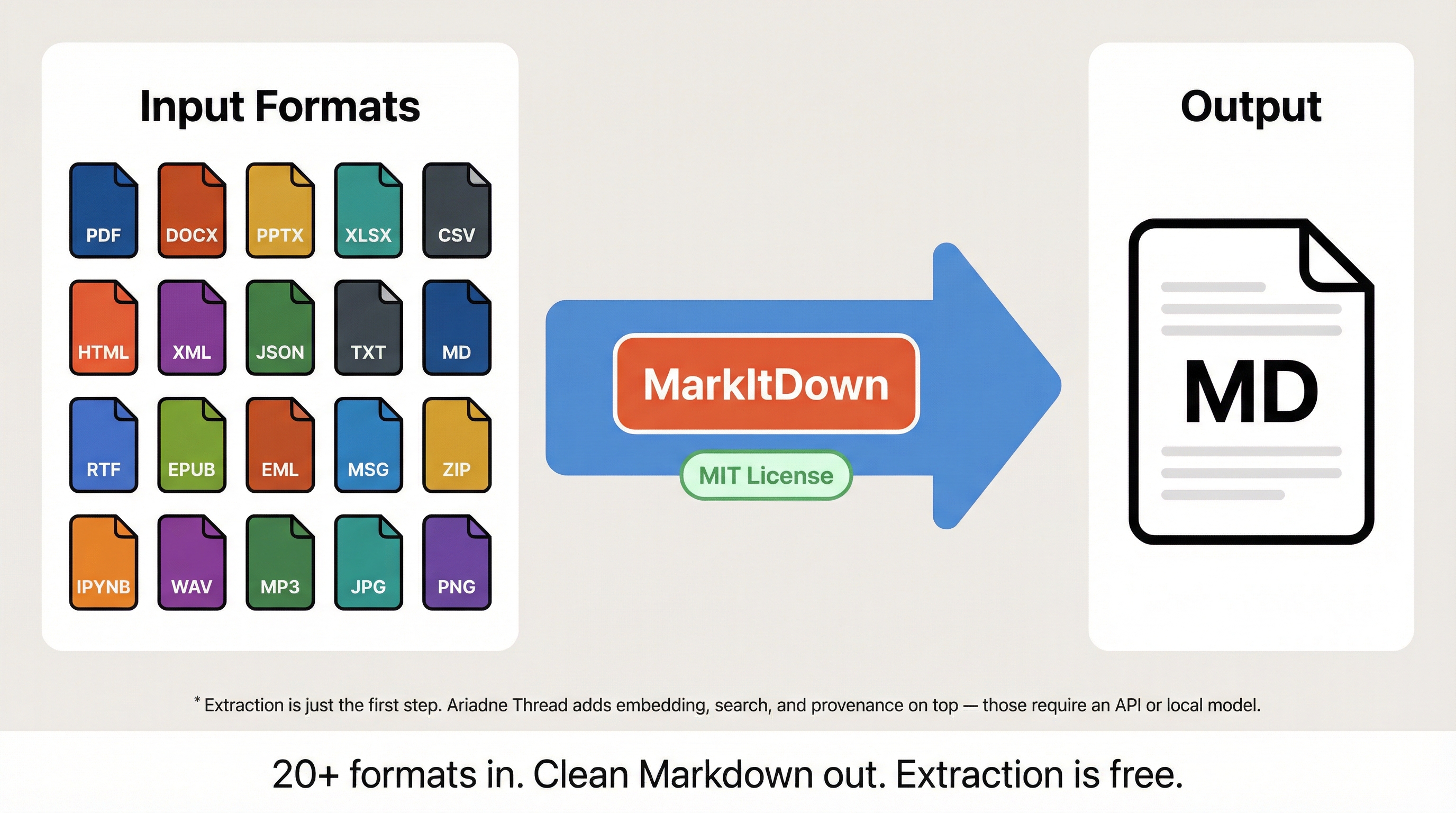
Works well: PDF (text-layer), DOCX, PPTX, XLSX, CSV, HTML, XML, JSON, TXT, Markdown, RTF, EPUB, EML, MSG, ZIP, Jupyter notebooks, WAV, MP3.
Honest limitations: Scanned PDFs with no text layer get poor results — MarkItDown can’t do OCR. Legacy Office formats (.doc, .ppt) aren’t supported. Complex tables with merged cells use heuristics, not ML layout detection. Images need a vision API key for meaningful extraction.
Architecture
Ariadne Thread runs as a single container with a single Postgres database. No workers, no Redis, no message queue. Processing is inline. MCP and REST API share one HTTP port.
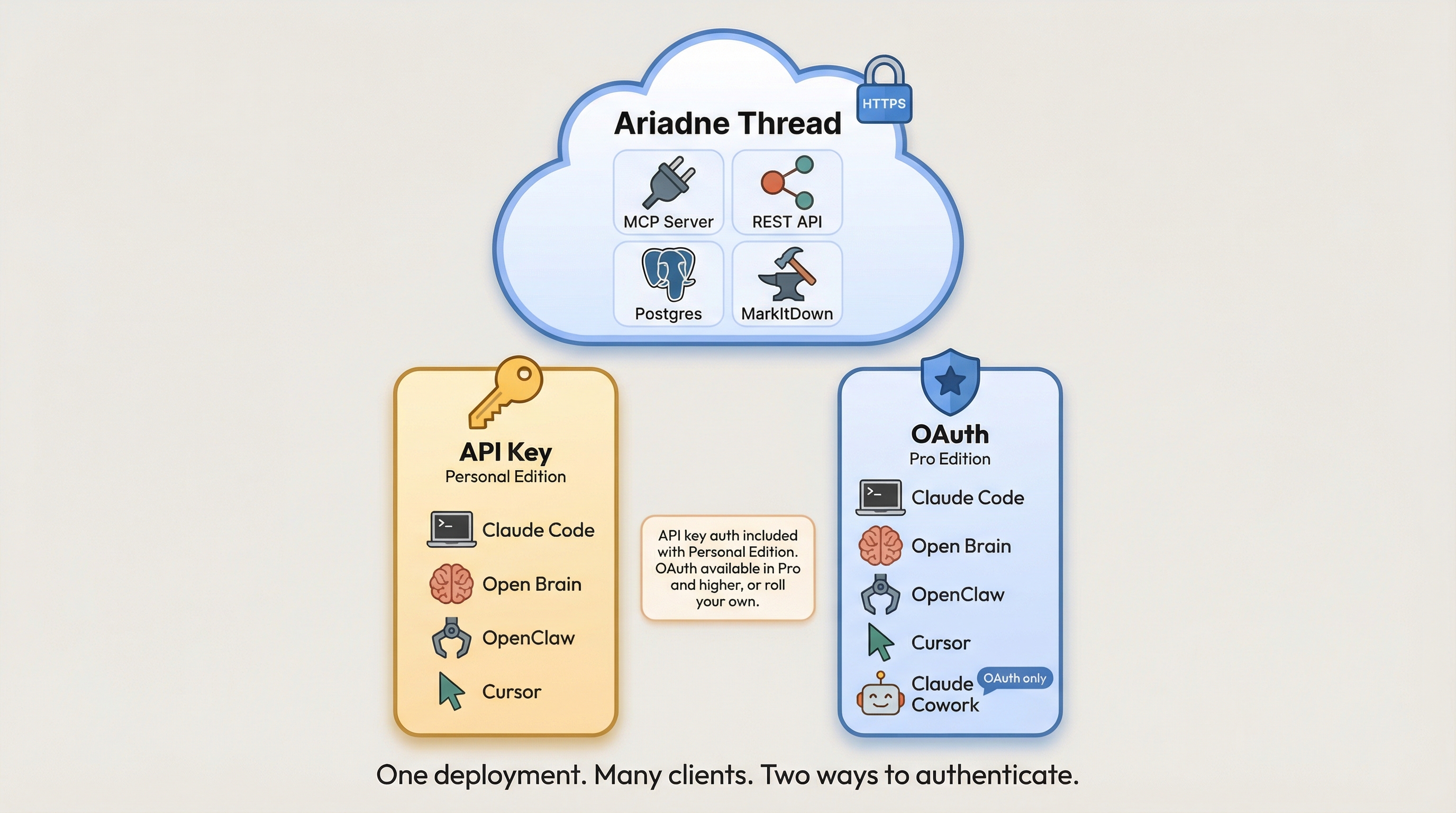
Any agent system that speaks MCP can connect: Claude Code, Open Brain, OpenClaw, Cursor, and more. REST API is also available for scripts and automation. Authentication is a single API key.
This simplicity is intentional. It’s a personal/single-user tool — not designed for multi-tenant SaaS. Managed editions (Pro, Business, Enterprise) are coming for teams that need multi-user access, OAuth, and enhanced extraction.
Search, don’t send
The key pattern once you’re set up: search first, send what matters.

Instead of stuffing entire documents into your agent’s context window, your agent searches Ariadne Thread and gets back the most relevant chunks with relevance scores. Then it passes just those chunks to the expensive model. Your agent gets better answers with fewer tokens.
What it costs
| Component | Cost | Notes |
|---|---|---|
| Hosting (Railway) | $0–5/mo | Free tier works for light use |
| Embedding API | ~$0.02/M tokens | ~$0.001 per document. Cheaper with Groq, DeepSeek, or local models |
| Vision API | ~$0.15/M tokens | Optional — only for images in documents |
| Extraction | $0 | Free via MarkItDown |
| Database | Included | Railway Postgres plugin |
A personal library of hundreds of documents costs a few dollars total to process.
Deploying

Railway is the simplest path — free tier, about 5 minutes to deploy. Fly.io works if you want scale-to-zero. Any Docker host works if you want full control. Same Dockerfile everywhere.
The deployment is five steps:
railway loginrailway initrailway add --plugin postgresql- Set three environment variables:
EMBEDDING_API_KEY,VISION_API_KEY,ARIADNE_API_KEY railway up
Then connect Claude Code with one command:
claude mcp add ariadne-thread https://your-url/mcp \
--transport http --scope user \
--header "X-API-Key:your-api-key"
Restart Claude Code and six tools are immediately available: convert_document, search, get_document, list_documents, list_collections, and ingest.
For agent builders
If you’re building with Open Brain, OpenClaw, or a custom framework, Ariadne Thread connects the same way — via MCP or REST API. Every agent call records provenance: which agent, which model, who triggered it. Even dedup skips are recorded, so you can always answer “which agents have touched this document?”
Collections let different agents organize documents without conflict. Search defaults to all collections, or scope to a specific one.
What it’s NOT
Being honest about boundaries:
- Not enterprise-scale — designed for personal use, not thousands of concurrent users
- Not multi-tenant — one API key, one user
- Not an OCR pipeline — can’t handle scanned documents well (yet)
- Not a document editor — extracts and retrieves, doesn’t modify
- Not locked to any vendor — works with any OpenAI-compatible embedding provider (OpenAI, Gemini, Groq, DeepSeek, Together AI, Mistral, Ollama, LM Studio, vLLM)
Getting started
The code is on GitHub. Nate B. Jones covers the token waste problem and introduces Ariadne Thread in Your Claude Sessions Cost 10x What They Should — the document ingestion deep-dive starts around 4:20. Also available as an article on Substack.
Deploy on Railway, connect your agents, and stop burning tokens on raw documents.
—Denson