Structured Data as LLM Tools: Why Diverse Tools Matter More Than Smart Models
Here’s something that surprised me after running 110 experimental trials on code analysis: the biggest lever for improving AI-assisted work isn’t a smarter model. It’s giving any performer — human or LLM — access to structurally diverse tools.
The performance hierarchy
For difficult analytical tasks — the kind where you need to find novel information and solutions, not just recall known facts — performance stacks up like this, from worst to best:
- LLMs without diverse tools
- LLMs with diverse tools
- New hires without diverse tools
- New hires with diverse tools
- Experienced employees without diverse tools
- Experienced employees with diverse tools
Notice the pattern. At every level, adding diverse tools improves performance. But the gaps between levels aren’t equal, and the reason why tells you something important about how humans and LLMs differ.
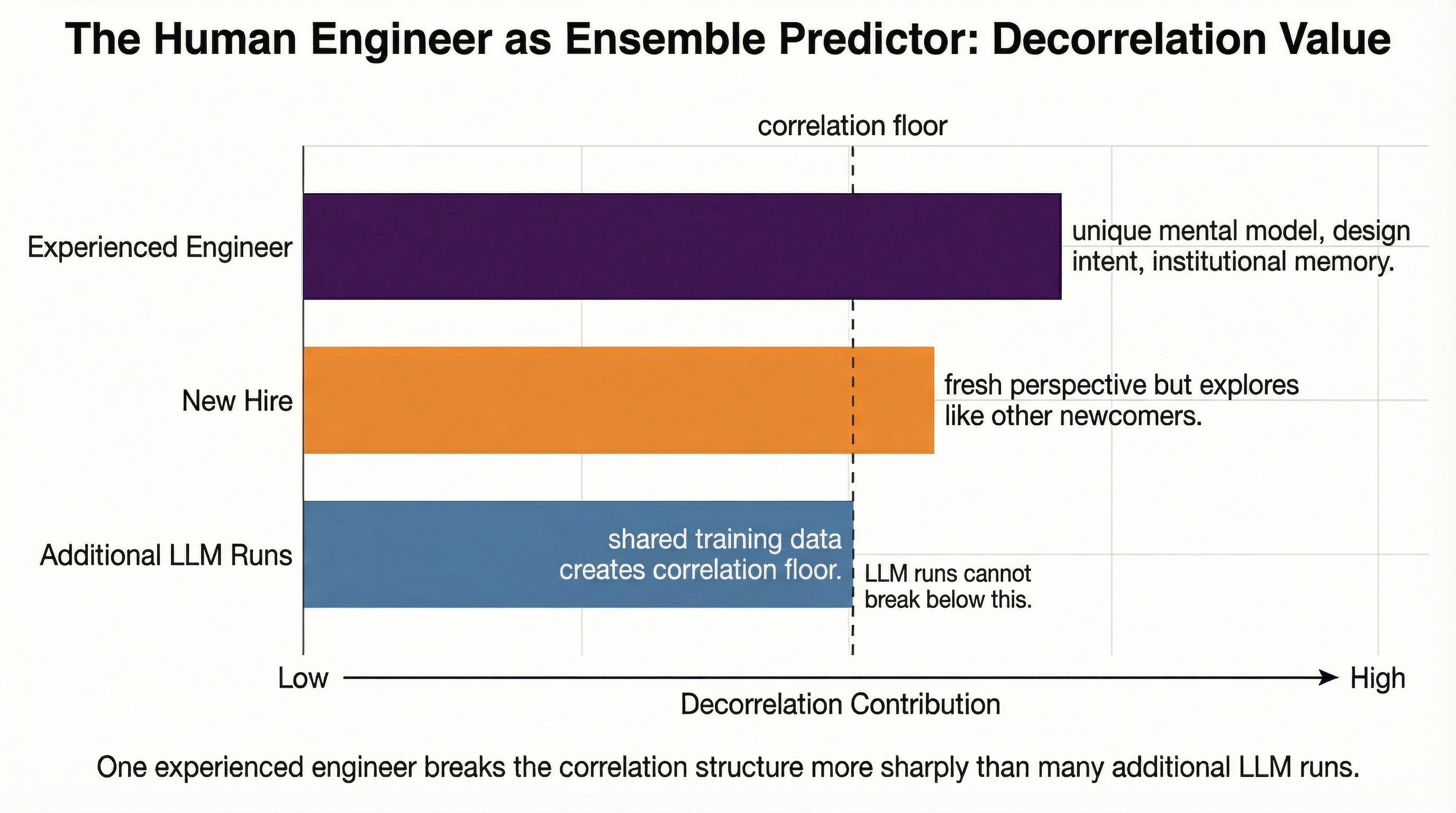
The main advantage humans have — even new hires — is that experience and judgment allow them to ignore large swaths of the search space that tend to trap LLMs. An LLM with diverse tools might find things a human would miss, but it gets there by searching and considering vastly more items than a human’s directed search. A human engineer looks at a codebase and immediately knows which modules matter and which are irrelevant. An LLM explores exhaustively and gets stuck in dead ends that a human would never enter.
This is why the gap between new hires and LLMs is larger than the gap between experienced employees and new hires. Experience sharpens the pruning — a senior engineer ignores even more of the space than a junior one — but the fundamental ability to prune at all is the bigger leap. New hires still have domain intuition, contextual judgment, and the ability to recognize when a search direction is unproductive. LLMs don’t prune; they enumerate.
This also explains what LLMs actually are in this hierarchy: they represent a diverse tool for humans. An experienced engineer who adds LLM-assisted analysis to their workflow gains genuine new coverage — the LLM’s exhaustive search finds things the human’s directed search skips over. The human’s pruning and the LLM’s breadth are genuinely complementary.
But an LLM is much less diverse as a tool for another LLM. Running the same model twice with slightly different prompts explores roughly the same region of the solution space. The runs are highly correlated — both LLMs make the same kind of exhaustive, unpruned traversals. To get genuine diversity for an LLM, you need tools that retrieve and structure information in fundamentally different ways.
The experiment that showed this
I built a Hypergraph Code Explorer (HCE) that represents code as a hypergraph — where a single edge can group multiple related entities (a caller, callee, argument types, return type) as one relationship, rather than decomposing them into pairwise connections that fabricate relationships that don’t exist.
Then I ran the Stable Garden Experiment: 11 analysis tasks across 4 Python codebases (20K to 250K lines of code), with 5 replications using HCE and 5 using text search (grep) as the control. Every finding was pooled and verified to build a gold standard of 1,060 symbols.
The results: 12.3% of symbols were found exclusively by HCE. 24.1% were found exclusively by grep. The combination beat both. These tools are genuinely decorrelated — they find different things because they traverse different structures.
The effect scaled with complexity. On small codebases, grep dominated (18.6% exclusive on httpx at 20K LOC vs. HCE’s 4.9%). On large codebases, the structural tool dominated (HCE found 26.0% exclusive on Django at 250K LOC vs. grep’s 3.9%). The harder the problem, the more tool diversity matters.
If the information is there, we can make the LLM use it
This is the key insight from the research, and it’s more powerful than it first appears.
If we can show through information science analysis that a corpus of data contains information relevant to a task — that the answer is structurally present in the data — then we know with confidence that we can use it to improve an agentic system’s response. The information content is a property of the data, not of the model consuming it.
This means that if you’ve fed structured data to an LLM and performance hasn’t improved, that’s not evidence the data is useless. It’s evidence that you haven’t yet found the right way to engineer the data into a context the model can exploit. The information is there. The problem is the interface.
This reframes the engineering challenge entirely. Instead of asking “can AI use this data?” you ask “how do I restructure this data so the AI can use it?” The answer is always findable because the information content is provably present. You might need to precompute relationships, build typed edges, create indexes that map to the questions the model will ask — but the destination is guaranteed to exist.
I formalized this as a four-stage methodology:
Stage 1 — Identify data with known information content. Find the deterministic structural relationships in your domain. In code, it’s ASTs and call graphs. In law, statute cross-references. In medicine, drug interaction databases. In supply chains, component-supplier-certification traceability.
Stage 2 — Test whether the LLM can use it as-is. Give it to the model raw. If performance improves, great — skip to Stage 4. If not, diagnose why: is the data not relevant to this task, is it not reaching the model, or does the model not know how to interpret it?
Stage 3 — Precompute better structure. Transform the data into a format that maps directly to how the LLM will query it. This is where the engineering happens. In my case, it meant building typed hyperedges (CALLS, INHERITS, IMPORTS) that correspond to the questions analysts actually ask.
Stage 4 — Measure diversity through exclusive discoveries. Run the new tool alongside your existing approach, pool results, verify, and count what each finds that the other misses. If there’s complementarity, invest. If not, save your money.
The critical point: if you’ve confirmed the information content in Stage 1, a failure in Stage 2 sends you to Stage 3, not back to the drawing board. You know the data has value. You just need to make it accessible.
The five classes of problem difficulty
Not all tasks benefit equally from tool diversity. I developed a taxonomy based on two axes — how hard it is to search for answers and how hard it is to verify them:
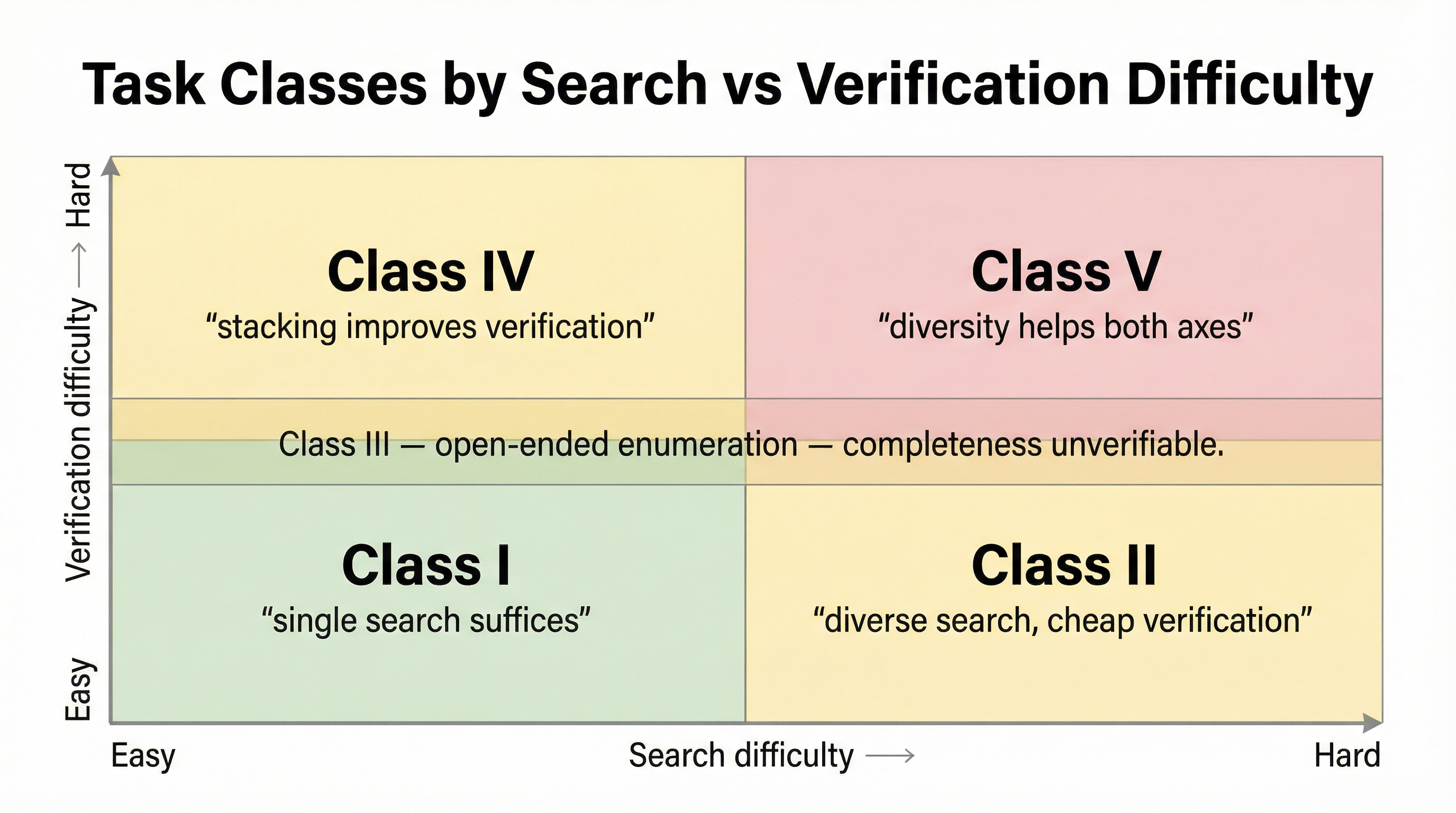
Class I — Easy search, easy verification. Looking up a single function definition. One tool run suffices. Stacking adds little.
Class II — Hard search, easy verification. Finding all implementations of an interface across a large codebase. Search is hard because the implementations are scattered, but once you find one, verifying it is trivial. Diverse search tools help enormously here — each tool finds implementations the other misses, and verification is cheap.
Class III — Easy per-item search, impossible completeness verification. Blast radius analysis, drug interaction discovery, dependency mapping. Each individual finding is easy to verify, but you can never prove you’ve found everything. This is where stacking is most naturally valuable — every additional diverse tool run expands the known set.
Class IV — Easy search, hard verification. Code review, security audits. Finding candidate issues is straightforward, but confirming whether something is actually a vulnerability requires deep analysis. Stacking helps by providing multiple independent assessments of the same findings.
Class V — Hard search, hard verification. Architectural analysis, complex system design evaluation. Both finding relevant information and evaluating it are difficult. This is where tool diversity provides the highest value — both the search and verification axes benefit from diverse approaches.
The taxonomy tells you where to invest. If your work is mostly Class I, don’t bother with tool stacking. If it’s Class III or V, diverse tools aren’t optional — they’re how you find the things a single approach will always miss.
The economics
Whether stacking is worth it depends on your domain’s cost structure. In blast radius analysis, missing a dependency (false negative) means a production outage — stacking to maximize coverage pays for itself. In medical diagnosis, both false positives and false negatives can be catastrophic — stacking is most valuable precisely because both levers matter. Map out your confusion matrix costs, and the investment math becomes clear.
What this means for teams
If you’re building agentic systems and care about reliability, the implication is practical: don’t just make your models smarter. Make your tools more diverse. And when you have structured data in your domain that your current AI tools can’t see, treat that as an engineering problem with a guaranteed solution, not an open research question.
The information is there. Build the interface.
—Denson